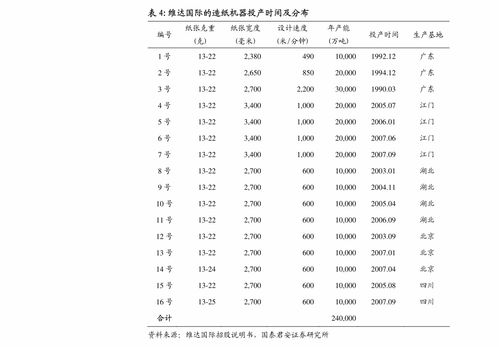
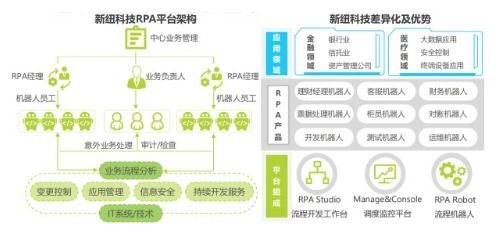
在當今數字化營銷時代,企業宣傳片已成為品牌傳播的重要工具。井字鍵影視憑借專業的技術服務與豐富的制作經驗,為您解析企業宣傳片背后的技術要點與創作流程。
專業的前期策劃是宣傳片成功的基礎。我們的團隊會深入了解企業文化和產品特點,結合目標受眾的需求,制定創意方案和分鏡頭腳本。通過市場調研和競品分析,確保宣傳片內容兼具吸引力和說服力。
拍攝環節采用先進的設備與技術。井字鍵影視運用高清攝像機、無人機航拍、燈光控制系統等專業器材,保障畫面質量與視覺效果。同時,我們注重場景布置與構圖設計,通過多角度拍攝和動態鏡頭,增強視覺沖擊力。
進入后期制作階段,我們的技術服務涵蓋剪輯、配音、特效和調色等多個方面。使用專業的剪輯軟件如Adobe Premiere和Final Cut Pro,確保畫面流暢過渡;通過音頻處理技術,提升配音和背景音樂的質量;結合CGI特效和動態圖形,為宣傳片增添科技感與創意元素。
井字鍵影視還提供多渠道發布與優化服務。我們會根據平臺特性(如社交媒體、官網或展會)調整視頻格式,并利用SEO和數據分析技術,幫助提升宣傳片的曝光率和傳播效果。
井字鍵影視致力于通過全方位的技術服務,助力企業打造高質量、有影響力的宣傳片,推動品牌形象與市場價值的提升。